Early classification of time series with double deep Q network
Reinforcement learning is typically implemented in an online setting, where the agent starts off making stupid actions and learns through a feedback loop with the environment's reward system. As it continues, the agent becomes more capable.
This style of reinforcement learning is extremely suitablem for episodic games as each episode is well defined and upon each iteration the game can be restarted and the agent can try again optimizing its interal decision making process depending on which algorithm is used. For applications where episodes are difficult or unable to be simulated this is not the case. We can not just restart the system in a new environment for online learning and generate a new set of actions and feedbacks for the agent to learn from.
On a similar note, under an online application, there is no use of any historical data collected by a separate agent or model. Naively training on historical action-reward pairs will result in biased training set as we cannot guarantee that the action space has been effectively explored with the other method.
This can seemingly limit the application of RL to well contained and seemingly contrived applications. Whereas most common problems in data science are muddy and unclear where environments and reward systems are not well defined and deploying completely naive models to learn in an online setting is risky and could prove costly.
An application which overcomes some of these limitation is the use of the RL in classifying multivariate sequences in a set of time series. This approach has been outlined in several papers by C. Martinez G. Perrin and E. Ramasso (Refs 1 and 2) and the general concept is covered in the review article by A. Gupta et al.
In these works they propose and implement a Double Deep Q Network agent which at each time step of the sequence will either classify the sequence to a set of pre-defined $k$ classes or delay the action to the next time step. The agent's preference for early classification or waiting until it is more certain can be tuned with hyperparameters.
Below I will show an implementation of this early classification with RL using Pytorch.
Setting up the Environment
Unlike other application of RL where there is a predefined environment set up in a gym API and our primary job is to set up an agent which chooses an action and receives a reward. In this situation we also need to set up our environment class. This evironment class will have have to receive actions and return particular rewards. The latter paper by Martinez et al. describes two different approaches to the reward function of the environment. In the repo we have implemented both approaches but we will only discuss the shaped reward function here.
Shaped reward function
This time series classification specific reward function has the delay reward shaped such that the longer you delay the classification, the larger the penalty you receive. This explicitly encodes the decay of the reward function over time in the environmental reward and the paper suggests having the agent not discount the future rewards they receive (\gamma = 1).
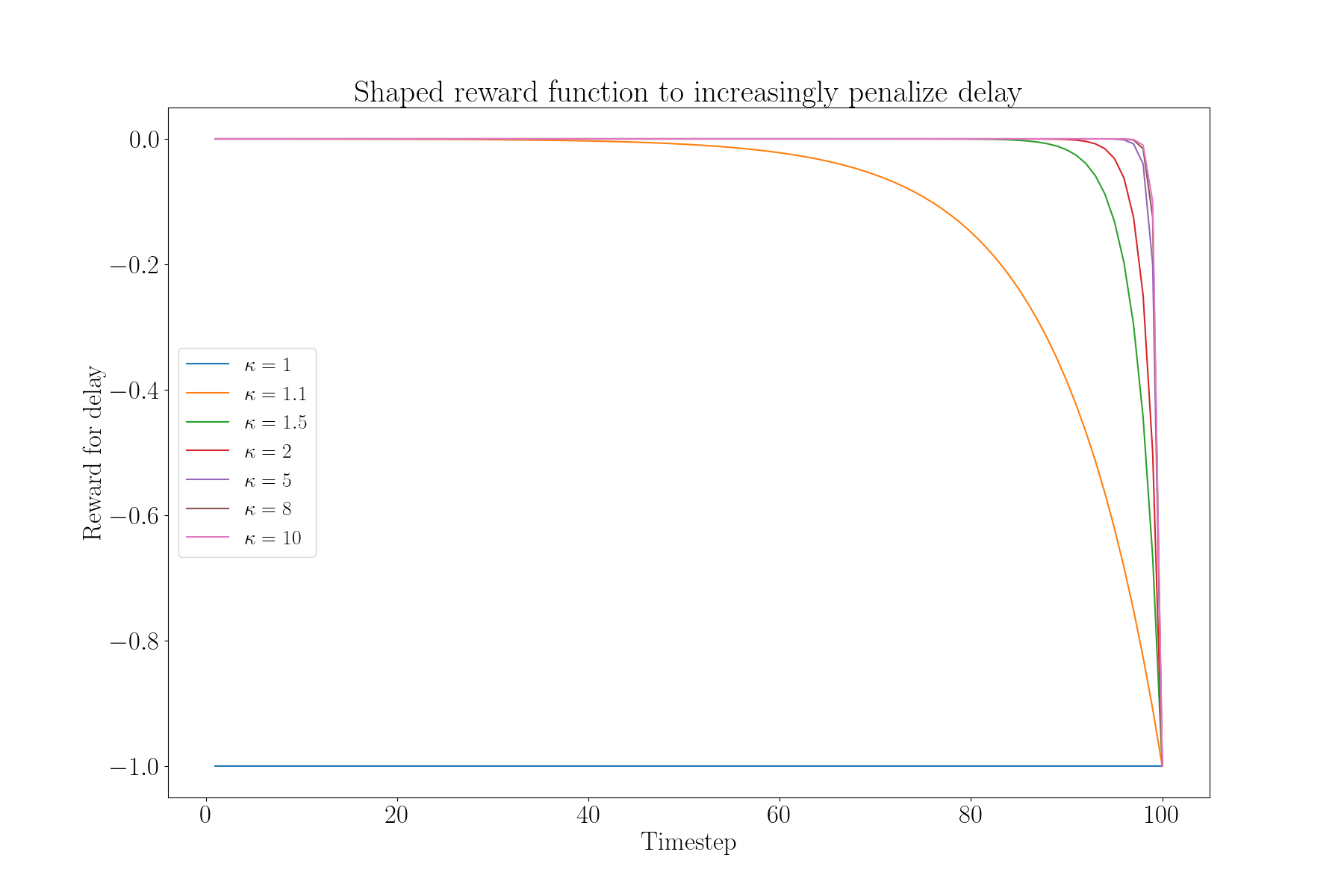
The shaped reward function is:
$$ \begin{aligned} a &= \text{action} \\ t &= \text{timestep in sequence} \\ T &= \text{total length of sequence} \\ r(a, t; T, \lambda, \kappa) &= \begin{cases} 1 & a \neq 0 \text{ and } a \text{ is correct}\\ -1 & a \neq 0 \text{ and } a \text{ is incorrect}\\ -\dfrac{\lambda}{\kappa^{T-t}} & a = 0 \end{cases} \end{aligned} $$
This is simplified compared to the one suggested in the above papers. Here $\lambda$ and $\kappa$ are tunable hyperparameters which optimize whether the agent prioritizes quicker classification of accuracy.
$\lambda$ :Tunes the importance of earliness compared to accuracy. Linearly scales the magnitude of the delay penalty
$\kappa$ : Tunes the penality of the delay as the sequence progresses.
Data preparation
One of the benefits of this application of RL is that we aren’t significantly affected by the downsides of offline RL learning. A problem with offline RL learning is that we don’t have counter-factual states given different actions than the ones taken. This can leads to poor exploration of the state-action space. For early classification, since every action but one is a terminal action, we can treat a training set time series of a given sequence as just a series of 'delay' actions. Then for every time step we can calculate the given reward of all other actions and the associated reward given the true class label. This will results in an exhaustive set of training tuples.
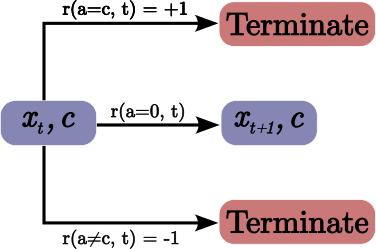
For example, for a time series with 3 time steps (states) and 2 possible classes a and b. Assume that the true label is a and we use discount reward function (no reward for delay). The training tuples from this will be.
Delayed action tuples
| State | Action | Reward | Next state |
|---|---|---|---|
| state 1 | delay | reward=0 | state 2 |
| state 2 | delay | reward=0 | state 3 |
| state 3 | delay | reward=0 | None |
| state 1 | a | reward=1 | None |
| state 2 | a | reward=1 | None |
| state 3 | a | reward=1 | None |
| state 1 | b | reward=-1 | None |
| state 2 | b | reward=-1 | None |
| state 3 | b | reward=-1 | None |
For a dataset with dimensions [number of sequences, number of timesteps, number of features] an exhaustive training set is generated by the env class in the repo. Multivariate datasets A repository of open, multivariate datasets for time classification can be found here. Each dataset contains sequences with a constant number of time steps and a set number of features at each timestep. Each sequence is labeled as a class. Heart anomaly dataset One of the datasets contains cardio measurements for several different patients over time. The provided description of the data is
Training set Sequences : 204 Time steps in sequence : 405 Classes : [normal, abnormal] Class ratio : [0.28, 0.72] Test set Sequences : 205 Time steps in sequence : 405 Classes : [normal, abnormal] Class ratio : [0.28, 0.72]
We can just batch generate the training and evaluation data. Using the env class method
env.load_exhaustive_dataset(self, data_dict) where data_dict is a dictionary containing the data
and metadata for the heartbeat data. This will generate the exhaustive set of training tuples
described above that will be passed to the agent for training.
Each tuple has the structure q_tpl = (state, action, reward, next_state, terminal, is_last)
A placeholder next_state is used if the state is terminal.
For the evaluation data, for all timesteps the class method env.load_eval_data(data_dict, data_type = 'TEST')
generates the tuple structure (state, label, timestep, is_last).
def load_exhaustive_dataset(self, data_dict):
"""
Offline generation of training and validation training set. A benefit of this classification
or delay problem is that for each training sequence we have, for each timestep we can
calculate rewards and next_states for every action. This is because all actions except
"delay" terminates the sequence (No next state) and "delay" moves us to the next timestep in
the data. Therefore we can generate an exhaustive training and validation set.
Keyword Arguments:
data_dict (dictionary): dictionary with numpy dataset and metadata
"""
data = data_dict['data']
labels = data_dict['labels']
classes = data_dict['class_list']
action_dict = data_dict['action_dict']
num_feats = data_dict['num_feats']
# Define specific environment information. Instantiated as Nones.
self.num_feats = num_feats
self.class_list = classes
self.action_dict = action_dict
# Reverse action dictionary to get actions asscociated with true labels.
rev_action_dict = dict((v, k) for k, v in action_dict.items())
labels = [rev_action_dict[i] for i in labels]
# print(f"True labels: {labels}")
# print(data[0])
# Generate all possible training q tuples from offline data
data_tuples = []
num_actions = len(self.class_list ) + 1
exhaustive_data = []
# Iterate over sequences (first axis of data)
for i in range(data.shape[0]):
num_timesteps = data[i].shape[0]
# Iterate of each timestep of sequence
for t in range(num_timesteps):
# Append state as contextual features of timestep.
state = data[i][t]
# Apply all actions to timestep.
for action in range(num_actions):
# print(action)
if t == num_timesteps-1:
is_last = True
else:
is_last = False
reward = self._gen_reward(label=labels[i], action=action, timestep=t+1, is_last=is_last, seq_length=num_timesteps)
# Get next state of sequence given action.
if action == 0:
if not is_last:
next_state = data[i][t+1]
terminal = 0
else:
next_state = np.zeros(num_feats)
terminal = 1
else:
# Placeholder terminal state. Multiplied out in pytorch.
next_state = np.zeros(num_feats)
terminal = 1
q_tpl = (state, action, reward, next_state, terminal, is_last)
# Append tuple to exhaustive data.
exhaustive_data.append(q_tpl)
return exhaustive_data
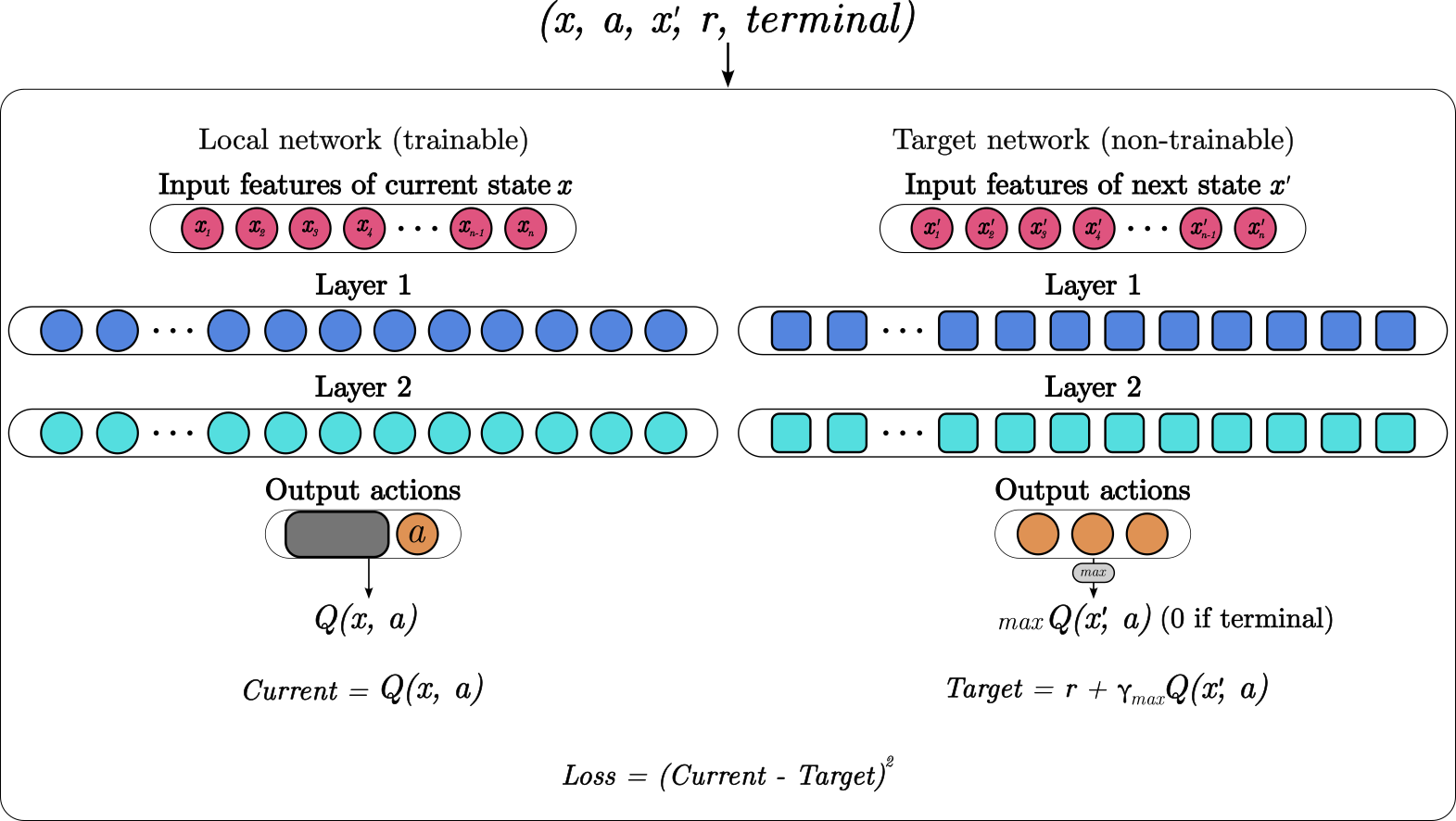
Setting up the agent
The RL agent uses a double deep Q network to learn the Q(x, a) functions. It is implemented in pytorch. We update the target DQN after every 20 batches or at the end of every epoch.
Double DQN architecture
Training
We implemented a DDQN with the following parameters * Two fully-connected, linearly activated hidden layers. * Both hidden layers have 128 neurons. * Learning rate exponential decay scheduler. Initial lr = 0.0001, decay factor = 0.9. * Batch size = 128. * Number of epochs = 50 (No early stopping). * Update target DQN with local DQN parameters after every 20 batches and every epoch.
def train_offline(self, epochs, batch_size, train_dataset, val_dataset=None, target_update_type='batch', update_batches=20, tau=1e-3, save_model=None):
"""
Pretrain the model with historical data. This is essentially like copying all the data into
the experience replay and training on it.
Keyword Args:
epochs (int) : Number of epochs to train over.
batch_size (int): size of batch to train at once.
train_dataset (Pytorch dataset): Training Dataset containing only tuples of
(state, reward, next_state, terminal_flag, is_last).
val_dataset (Pytorch dataset): Validation Dataset containing only tuples of
(state, reward, next_state, terminal_flag, is_last).
target_update_type (str) : One of 'batch' or 'soft'. Determines how to target QNN
is updated.
update_batches (int) : number of batched required to update target model.
tau (float): interpolation parameter for soft update.
save_model (Boolean) : Whether to save to model as a pickle file.
"""
# Load dataset into a loader to iterate.
loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
if val_dataset:
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
# Track historical training loss
train_loss_hist = []
# Track historical validation loss
val_loss_hist = []
print("Training")
for e in range(epochs):
# Track epoch loss
train_epoch_loss= []
for i, batch in enumerate(loader):
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch, _ = batch
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch = \
state_batch.to(device), action_batch.to(device), reward_batch.to(device), next_state_batch.to(device), terminal_batch.to(device)
action_batch = action_batch.reshape((action_batch.shape[0], 1))
criterion = torch.nn.MSELoss()
# Set the local NN for training. This will update the weights each batch.
self.qnetwork_local.train()
# Set the target NN for evaluation
# Target model is one with which we need to get our target (next state Q values).
# So that when we do a forward pass with target model it does not calculate gradient.
# We will update target model weights with soft_update function
self.qnetwork_target.eval()
# Calculate Q values of current state for the action that is taken. This is done with
# a forward pass of out local model.
q_values = self.qnetwork_local(state_batch.float()).gather(1,action_batch)
# calculate the max Q values of the next state after the action with the target network.
# Choose the Q - value with the largest value (best action). Terminal state logic is
# implemented in the following step. Q values for the placeholder will be used instead.
with torch.no_grad():
next_q_values = self.qnetwork_target(next_state_batch.float()).detach().max(1)[0].unsqueeze(1)
# Generate the target from the reward and the Q - value of the next state. If this was a
# terminal state/action, only use the reward.
target = reward_batch + self.gamma*next_q_values.reshape(next_q_values.shape[0])*(1 - terminal_batch.float())
current = q_values.reshape(q_values.shape[0])
# Confirm dtype
target = target.to(torch.float32)
current = current.to(torch.float32)
# Loss between target and current to minimize.
batch_train_loss = criterion(current, target)
self.optimizer.zero_grad()
batch_train_loss.backward()
train_epoch_loss.append(batch_train_loss.item())
self.optimizer.step()
if target_update_type == 'soft':
# Soft update target QNN
self._soft_update_target(self.qnetwork_local,self.qnetwork_target,tau)
if target_update_type == 'batch' and i % update_batches == 0:
# print("Updating target nn")
self._batch_update_target(self.qnetwork_local,self.qnetwork_target)
# Copy final local qnn to target qnn
self._batch_update_target(self.qnetwork_local, self.qnetwork_target)
# Calculate epoch loss
train_epoch_loss = sum(train_epoch_loss)/len(train_epoch_loss)
train_loss_hist.append(train_epoch_loss)
if len(train_loss_hist) >1:
train_delta = train_loss_hist[-1] - train_loss_hist[-2]
train_perc_delta = (train_loss_hist[-1] - train_loss_hist[-2])/(train_loss_hist[-2])*100
else:
train_perc_delta = 0.0
train_delta = 0.0
if self.scheduler:
self.scheduler.step()
# Perform validation
# TODO: Add early stopping logic to prevent overfitting
if val_dataset:
val_epoch_loss = []
with torch.no_grad():
for i, batch in enumerate(val_loader):
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch, _ = batch
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch = \
state_batch.to(device), action_batch.to(device), reward_batch.to(device), next_state_batch.to(device), terminal_batch.to(device)
action_batch = action_batch.reshape((action_batch.shape[0], 1))
q_values = self.qnetwork_target(state_batch.float()).gather(1,action_batch)
next_q_values = self.qnetwork_target(next_state_batch.float()).detach().max(1)[0].unsqueeze(1)
target = reward_batch + self.gamma*next_q_values.reshape(next_q_values.shape[0])*(1 - terminal_batch.float())
current = q_values.reshape(q_values.shape[0])
batch_val_loss = criterion(current, target)
val_epoch_loss.append(batch_val_loss.item())
val_epoch_loss = sum(val_epoch_loss)/len(val_epoch_loss)
val_loss_hist.append(val_epoch_loss)
if len(val_loss_hist) > 1:
val_perc_delta = (val_loss_hist[-1] - val_loss_hist[-2])/(val_loss_hist[-2])*100
val_delta = (val_loss_hist[-1] - val_loss_hist[-2])
else:
val_perc_delta = 0.0
val_delta = 0.0
else:
val_epoch_loss = 0.0
val_perc_delta = 0.0
print(f"Epoch {e}: Train Loss: {train_epoch_loss:.3f} ({train_delta:.3f}, {train_perc_delta:.3f}%) \t Val Loss: {val_epoch_loss:.3f} ({val_delta:.3f}, {val_perc_delta:.3f} %) \t lr: {self.optimizer.param_groups[0]['lr']:.3g}")
if save_model:
filename = os.path.join(MODELS_DIR, f'{self.agent_name}.pt')
torch.save(self.qnetwork_target.state_dict(), filename)
return train_loss_hist, val_loss_hist
Results
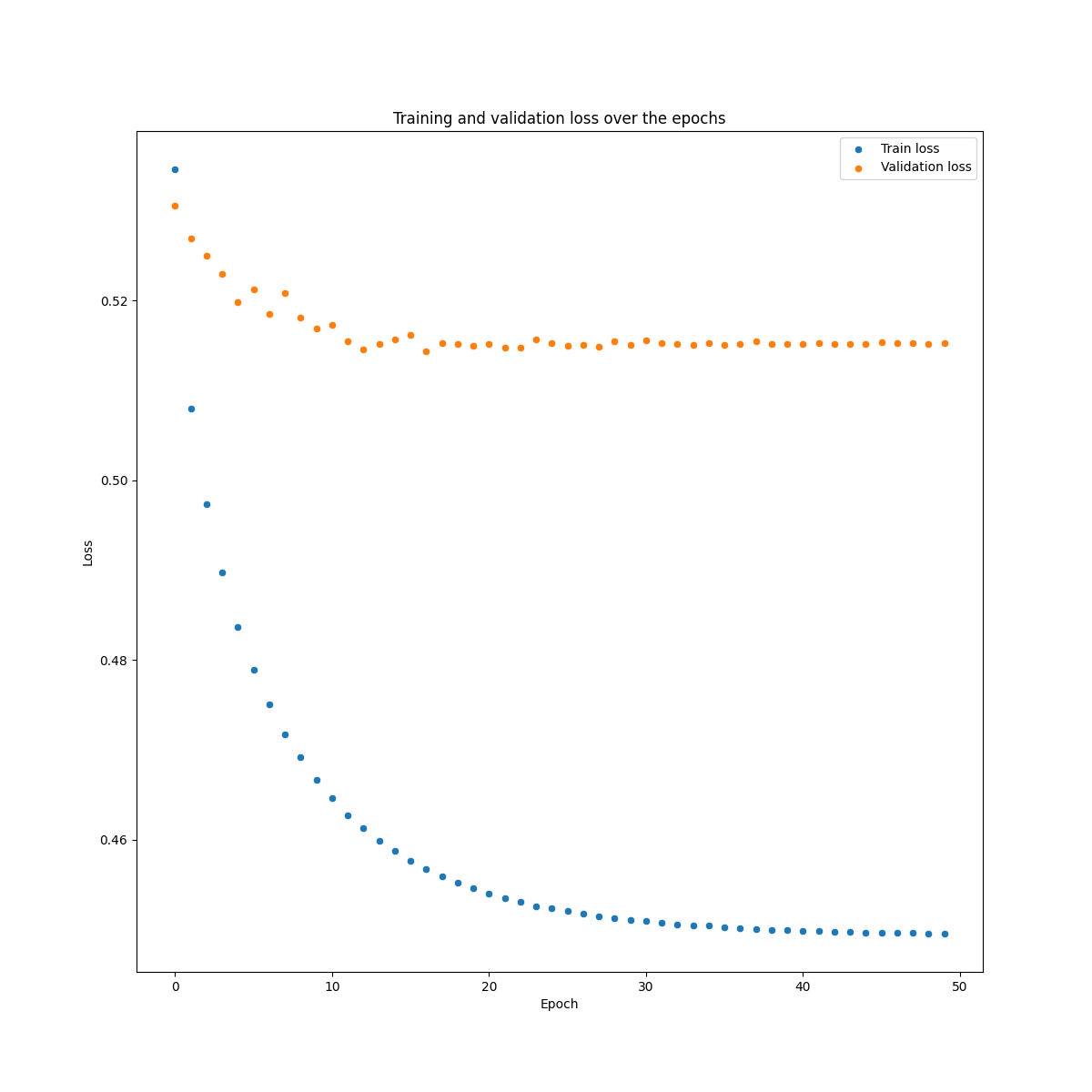
Here is a plot of one of the best performing set of hyperparameters. Lambda = 3, Kappa = 1.7 One thing we noted is that RL agent does not generalize too well on the test set (though it is better than the simple classification below).
There are two overall metrics to judge the performance of the agent. Accuracy of classification. For the accuracy we used the f1-score, specifically the weighted f1-score from the sklearn module (f1-score). How quick the classification occurred. The average classification time across all test samples. To get a sense of how the shaped reward hyper-parameters, lambda and kappa, affect these metrics we did a rough grid search. Large values of lambda (>100) gave nonsensical agents as these large negative delay rewards severely outweigh the classification rewards (|1|). Below is a plot of the total reward on the test set, the time classification score, and the f1_score against lambda for different values of kappa.
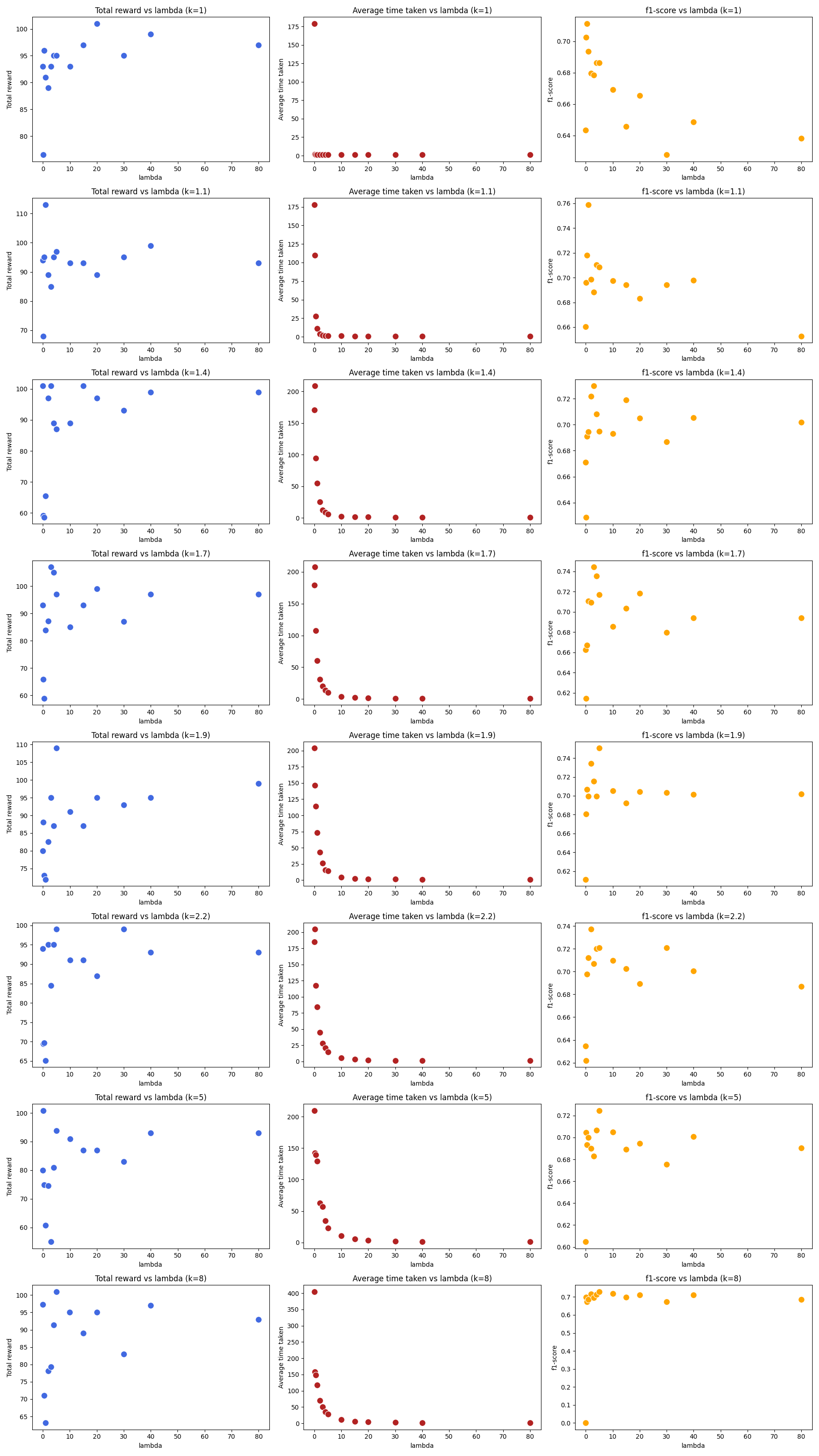
From these plots we can clearly see the effect of lambda on the time-score. For low values of lambda, the agents are indecisive, waiting a long time time to classify and in some cases never classifying. As lambda increases, delays get more and more expensive and the agents are incentivised to classify quickly as the penalty for not classifying far exceeds classification. This quickly converges to a point where the agent classifies immediately on the first timestep. The relationship between accuracy and lambda is less clear. This is understandable as there is no direct relationship between a delay action the accuracy of the prediction. However, we can make some broad conclusions. Having no delay penalty (lambda=0) gives very poor accuracy. This is most likely because in these cases there is no RL component and we are just left with a simple classifier as there there are no “next Q values“ for the target in the loss function. For most values of kappa, the best values for lambda are when it is comparable to the magnitude of the reward for correct classification (and negative reward for incorrect) which is simply 1 in the above search. Intuitively, this reward structure would allow the rewards for correct and incorrect classification actions to be meaningful in scale to the total reward and allows for better learning.
Benchmarking
We did some rough baseline ‘agents' to give a comparison anchor for our agents. These baseline agents do not use any RL mechanics but interact with the same environment to classify or delay and record the rewards. Currently we have built two baseline agents, a simple random action selection, and a NN classifier of with the same structure as our agent.
Simple NN classifier
We build a really simple (perhaps a strawman...) NN model with the same hidden structure as the DQN for the RL agent. The major difference is that the output layer only has two nodes corresponding to the two classes. That is, there is no delay action. We do a similar training process as above with the same hyperparameters. One major thing outcome of this is that the classifier does not generalize out of sample at all. There is not overall drop in the validation loss and it bounces around. Despite this, we apply the model the test set (validation set but whatever). We implement two different approaches for classifying throughout the sequence.
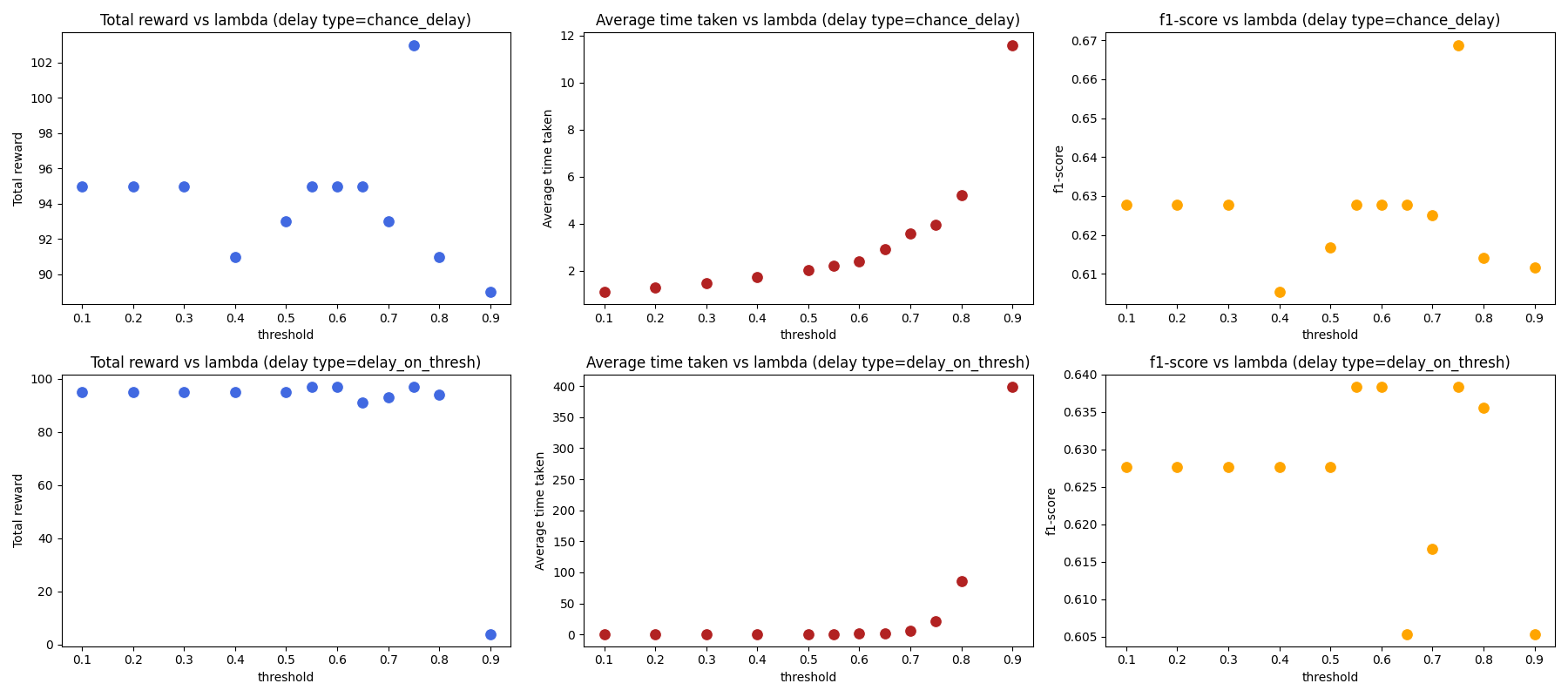
Threshold classification If the softmax probability of either class exceeds some threshold then it classifies. Otherwise it delays with some delay reward (default is 0) The simple model is terrible at distinguishing the two classes with probabilities rarely exceeding 0.6.
Set chance of delay
Delay or classify with some random chance. The classification will be arg max of the classifier at that time step. Here is a set of results for the simple classifier for both delay types at different thresholds.
Note: Thresholds <=0.5 for “delay on thresh“ are meaningless and correspond to immediate classification. The only interesting plot are the accuracy scores. Here, for all thresholds, the f1-score barely sits between 0.6-0.68 for all thresholds. Our RL agent outperformed this with f1-scores above 0.7 with certain hyper-parameters.
Overall, while the RL agent results are better than a simple classification agent this does not show how it compares to other techniques specifically designed for classification of time series data. Running benchmarks for those would be more enlightening but I am not too familiar with them and I needed to finish at some point.
Conclusion
From the above results we can see that the RL agent beat the simple classifier which struggled to generalize from independent features with no concept of time series. The RL agent demonstrated some capacity to learn and generalize but not to a large degree. This could be due to the nature of the dataset itself or could be improved by testing different DQN structures for the agent. We can see the effect that the lambda and kappa hyper-parameters have on the how the agent performs which reinforces that the agent is learning correctly based on the reward structure of the environment.
Early classification of time series with RL is an interesting approach to the problem and could be a promising solution in some cases. More work is required in benchmarking the effectiveness compared to more traditional early classification methods.
Complete code for Heart anomaly
Load data
from scipy.io import arff
import os
import pandas as pd
import numpy as np
import aeon
from aeon.datasets import load_from_tsfile
import torch
from torch.utils.data import DataLoader, Dataset
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
DATA_DIR = ###ENTER DATA PATH HERE
def load_data(data_name, data_type = 'TRAIN'):
print(data_name)
filename = os.path.join(os.path.join(DATA_DIR, data_name), f"{data_name}_{data_type}.ts")
print(filename)
x, y = load_from_tsfile(filename)
x = np.swapaxes(x, 1, 2)
return x, y
def strip_time_series(data, labels, ):
data_tmp = []
labels_tmp = []
for i in range(data.shape[0]):
data_tmp.append(data[i].squeeze())
labels_tmp.append(np.ones(data[i].shape[0])*labels[i])
data = np.concatenate(data_tmp, axis=0)
labels = np.concatenate(labels_tmp, axis=0)
return data, labels
class QDataset(Dataset):
def __init__(self, q_data):
self.q_data = q_data
def __len__(self):
return len(self.q_data)
def __getitem__(self, idx):
return self.q_data[idx]
class classDataset(Dataset):
def __init__(self, data, labels, eval=False):
if not eval:
data, labels = strip_time_series(data, labels)
self.data = torch.as_tensor(data, dtype=torch.float64)
self.labels = torch.as_tensor(labels, dtype=torch.long)
else:
# self.data = data
# self.labels = labels
self.data = torch.as_tensor(data, dtype=torch.float64)
self.labels = torch.as_tensor(labels, dtype=torch.long)
if len(self.data) != len(self.labels):
raise Exception("data and labels size does not match.")
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
Metrics
from sklearn.metrics import f1_score, confusion_matrix
from itertools import compress
def delay_score(eval_dict, class_list):
"""
Calculates a score on the how quickly the agent classifies a time series. It is the average
timestep across for classification divided by the length of the sequence. Lower scores are better.
"""
time_metrics = {}
# Total number of unclassified
total_classified = len([i for i in eval_dict['final_classification'] if i != 0])
total = len(eval_dict['final_classification'])
classified_ratio = total_classified/total
time_metrics['classified_ratio'] = classified_ratio
# class number of unclassified
for c in class_list:
class_bool = [True if a==c else False for a in eval_dict['true_labels']]
class_actions = list(compress(eval_dict['final_classification'], class_bool))
class_classified = len([i for i in class_actions if i != 0])
class_correct_classified = class_actions.count(c)
class_total = len(class_actions)
time_metrics[c] = {}
time_metrics[c]['total_classified_ratio'] = class_classified/class_total
time_metrics[c]['correct_classified_ratio'] = class_correct_classified/class_total
# Calculate total delay score
total_time = sum(eval_dict['classification_time'])
total_sequences = len(eval_dict['classification_time'])
time_metrics['total_time_score'] = total_time/total_sequences
# Calculate class delay score
for c in class_list:
class_bool = [True if a==c else False for a in eval_dict['true_labels']]
class_times = list(compress(eval_dict['classification_time'], class_bool))
class_time = sum(class_times)
class_total = len(class_times)
time_metrics[c]['class_time_score'] = class_time/class_total
return time_metrics
def accuracy_score(eval_dict):
"""
Calculates a score on the how quickly the agent classifies a time series. It is the average
timestep across for classification divided by the length of the sequence. Lower scores are better.
"""
acc_metrics = {}
# Accuracy scores
score = f1_score(eval_dict['true_labels'], eval_dict['final_classification'], average='weighted')
# Confusion matrix
cm = confusion_matrix(eval_dict['true_labels'], eval_dict['final_classification'])
acc_metrics['f1_score'] = score
acc_metrics['cm'] = cm
return acc_metrics
Environment
import os
import sys
import numpy as np
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
SRC_DIR = os.path.join(BASE_DIR, 'src')
UTILS_DIR = os.path.join(SRC_DIR, 'utils')
sys.path.append(SRC_DIR)
from utils.load_data import load_data
class env():
"""RL environement which defines an action and reward structure for the early stopping problem.
Keyword Args:
num_feats (int) : Number of contextual features at each timestep for a sequence.
class_list (list) : List of possible classifications of the sequence.
action_dict (dict) : Dictionary mapping integer actions to their classifications and a delay
action. Delay is typically 0.
lamb (float) : Hyperparamter of reward function. Tunes the importance of earliness compared
to accuracy. Linearly scales the magnitude of the delay penalty
kappa (float) : Hyperparamter of reward function. Tunes the penality of the delay as the
sequence progresses.
reward_type (string) : Either "discount" or "shaped".
"discount" -> Standard discount reward structure. Positive rewards for correct classification
negative for incorrect. No reward for delay. Discounted indirectly by agent's gamma.
"shaped" -> Time series specific reward structure. Environment explicit penalizes delays
based on "lamb" and "kappa" hyper parameters in addition to Positive rewards for
correct classification negative for incorrect.
terminal_delay_penalty (float): Magnitude of penalty for finishing sequence with no
classification. Handled implicity by shaped reward structure.
"""
def __init__(self, reward_type='discount', lamb=10, kappa=10, terminal_delay_penalty=0):
super(env, self).__init__()
self.num_feats = None
self.class_list = None
self.action_dict = None
self.lamb = lamb
self.kappa = kappa
self.reward_type = reward_type
self.terminal_delay_penalty = terminal_delay_penalty
def step(self, action):
"""
Perform a step along the time series for a single longitudinal data point
"""
pass
def _transition(self, action):
"""
For a given action return return the next state of the environment. Can also terminate.
"""
pass
def _discount_reward(self, label, action, timestep, is_last, seq_length):
"""
Standard reward which is discounted by the agent and not by the environment.
Keyword Args:
label (int) : True label of the sequence.
action (int) : Action chosen by the agent.
timestep (int) : Timestep in sequence action was taken.
is_last (Boolean) : Whether this is the final timestep in sequence.
seq_length (int) : Total number of timesteps in sequence.
"""
if is_last and action == 0:
# Penalize no classifying by end of sequence
r = self.terminal_delay_penalty
elif action == label:
# Correct classification
r = 1
elif (action != 0) and (action != label):
# Incorrect classification
r = -1
elif action == 0:
# Delay classification
r = 0
return r
def _shaped_reward(self, label, action, timestep, is_last, seq_length):
"""
Reward shaped by timeseries.
Keyword Args:
label (int) : True label of the sequence.
action (int) : Action chosen by the agent.
timestep (int) : Timestep in sequence action was taken.
is_last (Boolean) : Whether this is the final timestep in sequence.
seq_length (int) : Total number of timesteps in sequence.
"""
if action == label:
# Correct classification
r = 1
elif (action != 0) and (action != label):
# Incorrect classification
r = -1
elif action == 0:
# r = (-1)*self.lamb*(np.power(self.kappa, timestep)/(np.power(self.kappa, seq_length) - 1)) # Paper reward
r = (-1)*self.lamb/(np.power(self.kappa, seq_length - timestep)) # Simplified reward
if r == (-1)*np.inf:
r = 0.0
return r
def _gen_reward(self, label, action, timestep, is_last, seq_length):
"""
generate the reward for a given action
"""
if self.reward_type == 'discount':
return self._discount_reward(label, action, timestep, is_last, seq_length)
elif self.reward_type == 'shaped':
return self._shaped_reward(label, action, timestep, is_last, seq_length)
def load_exhaustive_dataset(self, data_dict):
"""
Offline generation of training and validation training set. A benefit of this classification
or delay problem is that for each training sequence we have, for each timestep we can
calculate rewards and next_states for every action. This is because all actions except
"delay" terminates the sequence (No next state) and "delay" moves us to the next timestep in
the data. Therefore we can generate an exhaustive training and validation set.
Keyword Arguments:
data_dict (dictionary): dictionary with numpy dataset and metadata
"""
data = data_dict['data']
labels = data_dict['labels']
classes = data_dict['class_list']
action_dict = data_dict['action_dict']
num_feats = data_dict['num_feats']
# Define specific environment information. Instantiated as Nones.
self.num_feats = num_feats
self.class_list = classes
self.action_dict = action_dict
# Reverse action dictionary to get actions asscociated with true labels.
rev_action_dict = dict((v, k) for k, v in action_dict.items())
labels = [rev_action_dict[i] for i in labels]
# print(f"True labels: {labels}")
# print(data[0])
# Generate all possible training q tuples from offline data
data_tuples = []
num_actions = len(self.class_list ) + 1
exhaustive_data = []
# Iterate over sequences (first axis of data)
for i in range(data.shape[0]):
num_timesteps = data[i].shape[0]
# Iterate of each timestep of sequence
for t in range(num_timesteps):
# Append state as contextual features of timestep.
state = data[i][t]
# Apply all actions to timestep.
for action in range(num_actions):
# print(action)
if t == num_timesteps-1:
is_last = True
else:
is_last = False
reward = self._gen_reward(label=labels[i], action=action, timestep=t+1, is_last=is_last, seq_length=num_timesteps)
# Get next state of sequence given action.
if action == 0:
if not is_last:
next_state = data[i][t+1]
terminal = 0
else:
next_state = np.zeros(num_feats)
terminal = 1
else:
# Placeholder terminal state. Multiplied out in pytorch.
next_state = np.zeros(num_feats)
terminal = 1
q_tpl = (state, action, reward, next_state, terminal, is_last)
# Append tuple to exhaustive data.
exhaustive_data.append(q_tpl)
return exhaustive_data
def load_eval_data(self, data_dict, data_type = 'TEST'):
"""
Generation of tuples of test set. Each tuple consists of the state, label, timestep and
whether it is the sequences final state. To be passed into agent.
Keyword Arguments:
data_dict (dictionary): dictionary with numpy dataset and metadata
"""
data = data_dict['data']
labels = data_dict['labels']
classes = data_dict['class_list']
action_dict = data_dict['action_dict']
num_feats = data_dict['num_feats']
rev_action_dict = dict((v, k) for k, v in action_dict.items())
labels = [rev_action_dict[i] for i in labels]
test_set = []
for i in range(data.shape[0]):
sample = []
num_timesteps = data[i].shape[0]
# print(num_timesteps)
for t in range(num_timesteps):
if t == num_timesteps-1:
is_last = True
else:
is_last = False
state = data[i][t]
label = labels[i]
timestep = t
sample.append((state, label, timestep, is_last))
test_set.append(sample)
return test_set
RL Agent
import torch
import torch.nn as nn
import torch.nn.functional as F
class QNetwork(nn.Module):
""" Actor (Policy) Model."""
def __init__(self, state_size, action_size, seed, fc1_unit=64, fc2_unit = 64):
"""
Initialize parameters and build model.
Params
=======
state_size (int): Dimension of each state
action_size (int): Dimension of each action
seed (int): Random seed
fc1_unit (int): Number of nodes in first hidden layer
fc2_unit (int): Number of nodes in second hidden layer
"""
super(QNetwork,self).__init__() ## calls __init__ method of nn.Module class
if seed:
self.seed = torch.manual_seed(seed)
self.fc1= nn.Linear(state_size,fc1_unit)
self.fc2 = nn.Linear(fc1_unit,fc2_unit)
self.fc3 = nn.Linear(fc2_unit,action_size)
def forward(self,x):
# x = state
"""
Build a network that maps state -> action values.
"""
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
import numpy as np
import random
import os
import sys
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
SRC_DIR = os.path.join(BASE_DIR, 'src')
UTILS_DIR = os.path.join(SRC_DIR, 'utils')
MODELS_DIR = os.path.join(SRC_DIR, 'trained_models')
sys.path.append(SRC_DIR)
from models.agent_nn import QNetwork
from torch.utils.data import DataLoader, Dataset
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Agent():
"""RL environement which defines an action and reward structure for the early stopping problem.
Keyword Args:
agent_name (string) : Name of the agent to save/load a model.
state_size (int) : Number of features defining each state.
action_size (int) : Number of possible classifications and the delay action.
env (env class) : Environment class.
learning_rate (float) : Update parameter for DQN
gamma (float) : Discount factor of future rewards.
tau (float) : Interpolation parameter for soft updating target DQN model with local DQN model.
"""
def __init__(self, agent_name, state_size, action_size, env, learning_rate=5e-4, gamma=0.9, tau=1e-3, layer_1_size=64, layer_2_size=64,seed=None, lr_sched='exponential'):
super(Agent, self).__init__()
self.agent_name = agent_name
self.state_size = state_size
self.action_size = action_size
self.seed = random.seed(seed)
self.env = env
self.layer_1_size = layer_1_size
self.layer_2_size = layer_2_size
# Hyperparameters
self.learning_rate = learning_rate
self.gamma = gamma
self.tau = tau
#Set up both the local and target networks. They must have identical structures
self.qnetwork_local = QNetwork(
state_size=self.state_size,
action_size=self.action_size,
seed=self.seed,
fc1_unit=self.layer_1_size,
fc2_unit=self.layer_2_size,
)
self.qnetwork_target = QNetwork(
state_size=self.state_size,
action_size=self.action_size,
seed=self.seed,
fc1_unit=self.layer_1_size,
fc2_unit=self.layer_2_size,
)
# Send networks to device
self.qnetwork_local.to(device)
self.qnetwork_target.to(device)
# self.load_model()
# Define the NN optimizer for the trainable network (local)
self.optimizer = optim.Adam(self.qnetwork_local.parameters(), lr=self.learning_rate)
if lr_sched == 'exponential':
self.scheduler = lr_scheduler.ExponentialLR(self.optimizer, gamma=0.9)
def load_model(self, filename=None):
if filename:
saved_name = filename
else:
saved_name = f"{self.agent_name}.pt"
path = os.path.join(MODELS_DIR, saved_name)
# Load the model into both DQNS
self.qnetwork_local.load_state_dict(torch.load(path))
self.qnetwork_target.load_state_dict(torch.load(path))
def _soft_update_target(self, local_model, target_model, tau):
"""
Update the target NN with the local parameters through interpolation every time step
Keyword Args:
local model (PyTorch model): weights will be copied from.
target model (PyTorch model): weights will be copied to.
tau (float) : Interpolation parameter for soft updating target DQN model with local DQN model.
"""
for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):
target_param.data.copy_(tau*local_param.data + (1-tau)*target_param.data)
def _batch_update_target(self, local_model, target_model):
"""
Update the target NN with the local parameters competely. Should be done after some number
of training batches on the local model.
Keyword Args:
local model (PyTorch model): weights will be copied from.
target model (PyTorch model): weights will be copied to.
"""
for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):
target_param.data.copy_(local_param.data)
def train_offline(self, epochs, batch_size, train_dataset, val_dataset=None, target_update_type='batch', update_batches=20, tau=1e-3, save_model=None):
"""
Pretrain the model with historical data. This is essentially like copying all the data into
the experience replay and training on it.
Keyword Args:
epochs (int) : Number of epochs to train over.
batch_size (int): size of batch to train at once.
train_dataset (Pytorch dataset): Training Dataset containing only tuples of
(state, reward, next_state, terminal_flag, is_last).
val_dataset (Pytorch dataset): Validation Dataset containing only tuples of
(state, reward, next_state, terminal_flag, is_last).
target_update_type (str) : One of 'batch' or 'soft'. Determines how to target QNN
is updated.
update_batches (int) : number of batched required to update target model.
tau (float): interpolation parameter for soft update.
save_model (Boolean) : Whether to save to model as a pickle file.
"""
# Load dataset into a loader to iterate.
loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
if val_dataset:
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
# Track historical training loss
train_loss_hist = []
# Track historical validation loss
val_loss_hist = []
print("Training")
for e in range(epochs):
# Track epoch loss
train_epoch_loss= []
for i, batch in enumerate(loader):
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch, _ = batch
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch = \
state_batch.to(device), action_batch.to(device), reward_batch.to(device), next_state_batch.to(device), terminal_batch.to(device)
action_batch = action_batch.reshape((action_batch.shape[0], 1))
criterion = torch.nn.MSELoss()
# Set the local NN for training. This will update the weights each batch.
self.qnetwork_local.train()
# Set the target NN for evaluation
# Target model is one with which we need to get our target (next state Q values).
# So that when we do a forward pass with target model it does not calculate gradient.
# We will update target model weights with soft_update function
self.qnetwork_target.eval()
# Calculate Q values of current state for the action that is taken. This is done with
# a forward pass of out local model.
q_values = self.qnetwork_local(state_batch.float()).gather(1,action_batch)
# calculate the max Q values of the next state after the action with the target network.
# Choose the Q - value with the largest value (best action). Terminal state logic is
# implemented in the following step. Q values for the placeholder will be used instead.
with torch.no_grad():
next_q_values = self.qnetwork_target(next_state_batch.float()).detach().max(1)[0].unsqueeze(1)
# Generate the target from the reward and the Q - value of the next state. If this was a
# terminal state/action, only use the reward.
target = reward_batch + self.gamma*next_q_values.reshape(next_q_values.shape[0])*(1 - terminal_batch.float())
current = q_values.reshape(q_values.shape[0])
# Confirm dtype
target = target.to(torch.float32)
current = current.to(torch.float32)
# Loss between target and current to minimize.
batch_train_loss = criterion(current, target)
self.optimizer.zero_grad()
batch_train_loss.backward()
train_epoch_loss.append(batch_train_loss.item())
self.optimizer.step()
if target_update_type == 'soft':
# Soft update target QNN
self._soft_update_target(self.qnetwork_local,self.qnetwork_target,tau)
if target_update_type == 'batch' and i % update_batches == 0:
# print("Updating target nn")
self._batch_update_target(self.qnetwork_local,self.qnetwork_target)
# Copy final local qnn to target qnn
self._batch_update_target(self.qnetwork_local, self.qnetwork_target)
# Calculate epoch loss
train_epoch_loss = sum(train_epoch_loss)/len(train_epoch_loss)
train_loss_hist.append(train_epoch_loss)
if len(train_loss_hist) >1:
train_delta = train_loss_hist[-1] - train_loss_hist[-2]
train_perc_delta = (train_loss_hist[-1] - train_loss_hist[-2])/(train_loss_hist[-2])*100
else:
train_perc_delta = 0.0
train_delta = 0.0
if self.scheduler:
self.scheduler.step()
# Perform validation
# TODO: Add early stopping logic to prevent overfitting
if val_dataset:
val_epoch_loss = []
with torch.no_grad():
for i, batch in enumerate(val_loader):
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch, _ = batch
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch = \
state_batch.to(device), action_batch.to(device), reward_batch.to(device), next_state_batch.to(device), terminal_batch.to(device)
action_batch = action_batch.reshape((action_batch.shape[0], 1))
q_values = self.qnetwork_target(state_batch.float()).gather(1,action_batch)
next_q_values = self.qnetwork_target(next_state_batch.float()).detach().max(1)[0].unsqueeze(1)
target = reward_batch + self.gamma*next_q_values.reshape(next_q_values.shape[0])*(1 - terminal_batch.float())
current = q_values.reshape(q_values.shape[0])
batch_val_loss = criterion(current, target)
val_epoch_loss.append(batch_val_loss.item())
val_epoch_loss = sum(val_epoch_loss)/len(val_epoch_loss)
val_loss_hist.append(val_epoch_loss)
if len(val_loss_hist) > 1:
val_perc_delta = (val_loss_hist[-1] - val_loss_hist[-2])/(val_loss_hist[-2])*100
val_delta = (val_loss_hist[-1] - val_loss_hist[-2])
else:
val_perc_delta = 0.0
val_delta = 0.0
else:
val_epoch_loss = 0.0
val_perc_delta = 0.0
print(f"Epoch {e}: Train Loss: {train_epoch_loss:.3f} ({train_delta:.3f}, {train_perc_delta:.3f}%) \t Val Loss: {val_epoch_loss:.3f} ({val_delta:.3f}, {val_perc_delta:.3f} %) \t lr: {self.optimizer.param_groups[0]['lr']:.3g}")
if save_model:
filename = os.path.join(MODELS_DIR, f'{self.agent_name}.pt')
torch.save(self.qnetwork_target.state_dict(), filename)
return train_loss_hist, val_loss_hist
def eval_offline(self, dataset):
"""
Evaluate the trained model on the test dataset. Returns raw actions and rewards.
Keyword Args:
dataset (Pytorch dataset): Dataset containing only tuples of
(state, terminal_flag, is_last).
"""
eval_dict = {}
rewards = []
self.qnetwork_target.eval()
total_reward = 0
sample_reward_list = []
classification_time = []
action_list = []
final_classification = []
true_labels = []
for i in dataset:
sample_reward = 0
counter = 0
total_timesteps = len(i)
actions = []
final_action = 0
for tpl in i:
state, label, timestep, is_last = tpl
with torch.no_grad():
action = self.qnetwork_target(torch.tensor(state).float().to(device)).detach().argmax()#(1)[0].unsqueeze(1)
actions.append(action.item())
# print(action)
reward = self.env._gen_reward(label=label, action=action, timestep=timestep+1, is_last=is_last, seq_length=total_timesteps)
total_reward += reward
sample_reward += reward
counter += 1
if action != 0:
final_action = action.item()
break
true_labels.append(label)
final_classification.append(final_action)
classification_time.append(counter)
sample_reward_list.append(sample_reward)
action_list.append(actions)
eval_dict['true_labels'] = true_labels
eval_dict['total_reward'] = total_reward
eval_dict['sample_reward_list'] = sample_reward_list
eval_dict['classification_time'] = classification_time
eval_dict['action_list'] = action_list
eval_dict['final_classification'] = final_classification
return eval_dict
Generate training grid plot
import os
import sys
import numpy as np
import pickle
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
DATA_DIR = os.path.join(BASE_DIR, 'data')
SRC_DIR = os.path.join(BASE_DIR, 'src')
MODELS_DIR = os.path.join(SRC_DIR, 'trained_models')
sys.path.append(SRC_DIR)
from agents.ts_agents import Agent
from utils.load_data import load_data, QDataset
from utils.metrics import delay_score, accuracy_score
from envs.environment import env
def run_grid_search(train_data_dict, val_data_dict, eval_dataset):
reward_type = ['shaped'] #['discount', 'shaped']
kappa = [1, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 2.2, 2.5, 2.8, 5, 8]
lamb = [0, 0.1, 0.5, 1, 2, 3, 4, 5, 10, 15, 20, 30, 40, 80, 100, 200, 400, 1000, 2000, 4000, 10000]
gamma = [0, 0.1, 0.2, 0.5, 0.9, 0.99, 1]
terminal_penalty = [0, -1, -5, -10]
lr = 0.0001
param_list = []
class_list = train_data_dict['action_dict'].keys()
for rt in reward_type:
if rt == 'shaped':
g = 1
term=0
for k in kappa:
for l in lamb:
param_list.append((rt, lr, g, l, k, term))
elif rt == 'discount':
l = None
k = None
for g in gamma:
for term in terminal_penalty:
param_list.append((rt, lr, g, l, k, term))
gs_dict = {}
for tpl in param_list:
rt, lr, g, l, k, term = tpl
print(f"Discount type: {rt}, gamma: {g}, lambda: {l}, kappa:{k}, terminal pen:{term}")
e = env(
reward_type=rt,
lamb=l,
kappa=k,
terminal_delay_penalty=term
)
train_q_data = e.load_exhaustive_dataset(data_dict=train_data_dict)
val_q_data = e.load_exhaustive_dataset(data_dict=val_data_dict)
train_dataset = QDataset(q_data=train_q_data)
val_dataset = QDataset(q_data=val_q_data)
agent = Agent(
agent_name='heartbeat',
state_size=61,
action_size=3,
env = e,
learning_rate=lr,
gamma=g,
tau=1e-3,
seed=None,
layer_1_size=128,
layer_2_size=128,
)
train_loss_hist, val_loss_hist = agent.train_offline(
epochs= 50,
batch_size=128,
train_dataset=train_dataset,
val_dataset=val_dataset,
)
result_dict = agent.eval_offline(dataset=eval_dataset)
delay_dict = delay_score(eval_dict=result_dict, class_list=class_list)
acc_dict = accuracy_score(eval_dict=result_dict)
gs_dict[tpl] = {}
gs_dict[tpl]['results'] = result_dict
gs_dict[tpl]['time_metrics'] = delay_dict
gs_dict[tpl]['acc_metrics'] = acc_dict
gs_dict[tpl]['training'] = train_loss_hist
gs_dict[tpl]['validation'] = val_loss_hist
with open(os.path.join(MODELS_DIR, 'lr_grid_search_results.pkl'), 'wb') as handle:
pickle.dump(gs_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)
def main():
print(BASE_DIR)
data_name = 'Heartbeat'
# Load training data
train_data, train_labels = load_data(data_name=data_name, data_type='TRAIN')
# Load testing data
test_data, test_labels = load_data(data_name=data_name, data_type='TEST')
class_list = np.unique(train_labels)
action_dict = {i+1: v for i, v in enumerate(class_list) }
action_dict[0] = 'Delay'
num_feats = train_data.shape[-1]
print(f"Classes: {class_list}")
print(f"Number of features {num_feats}")
print(f"Length of sequence {train_data.shape[1]}")
train_data_dict = {
'data' : train_data,
'labels' : train_labels,
'class_list' : class_list,
'action_dict' : action_dict,
'num_feats' : num_feats,
}
val_data_dict = {
'data' : test_data,
'labels' : test_labels,
'class_list' : class_list,
'action_dict' : action_dict,
'num_feats' : num_feats,
}
e = env(
reward_type='shaped', #'discount',
lamb=2,
kappa=2,
terminal_delay_penalty=0
)
train_q_data = e.load_exhaustive_dataset(data_dict=train_data_dict)
val_q_data = e.load_exhaustive_dataset(data_dict=val_data_dict)
train_dataset = QDataset(q_data=train_q_data)
val_dataset = QDataset(q_data=val_q_data)
agent = Agent(
agent_name='heartbeat',
state_size=num_feats,
action_size=len(action_dict.keys()),
env = e,
learning_rate=0.0001,
gamma=1,
tau=1e-3,
seed=None,
layer_1_size=128,
layer_2_size=128,
)
# Load model if exists
model_name = 'model' #'heartbeat.pt'
file_exists = os.path.exists(os.path.join(MODELS_DIR, model_name))
if file_exists:
agent.load_model(model_name)
print("Loaded pretrained model")
else:
agent.train_offline(
epochs= 30,
batch_size=128,
train_dataset=train_dataset,
val_dataset=val_dataset,
)
print("Trained new model")
eval_data = e.load_eval_data(data_dict=val_data_dict, data_type='TEST')
# # Truncate dataset for testing
eval_dataset = QDataset(q_data=eval_data)
run_grid_search(train_data_dict, val_data_dict, eval_dataset)
pass
if __name__ == "__main__":
main()
Classifier benchmark
import os
import sys
import numpy as np
import torch.optim as optim
import torch.nn as nn
import torch
from torch.utils.data import DataLoader, Dataset
import pickle
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
DATA_DIR = os.path.join(BASE_DIR, 'data')
SRC_DIR = os.path.join(BASE_DIR, 'src')
MODELS_DIR = os.path.join(SRC_DIR, 'trained_models')
sys.path.append(SRC_DIR)
from models.classification_nn import Classifier
from utils.load_data import load_data, strip_time_series, classDataset
from utils.metrics import delay_score, accuracy_score
from agents.benchmarks import agentClassifier
def raw():
print(BASE_DIR)
data_name = 'EthanolConcentration'
train_data, train_labels = load_data(data_name=data_name, data_type='TRAIN')
class_list = np.unique(train_labels)
class_dict = {i: v for i, v in enumerate(class_list)}
rev_class_dict = dict((v, k) for k, v in class_dict.items())
train_labels = [rev_class_dict[i] for i in train_labels]
num_feats = train_data.shape[-1]
print(train_data)
print(train_labels)
#Put into dataset
train_dataset = classDataset(data=train_data, labels=train_labels)
test_data, test_labels = load_data(data_name=data_name, data_type='TEST')
test_labels = [rev_class_dict[i] for i in test_labels]
test_dataset = classDataset(data=test_data, labels=test_labels)
classifier = Classifier(
input_size=3,
class_size=4
)
print(classifier)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(classifier.parameters(), lr=0.00001, momentum=0.5)
# Create dataloader
train_loader = DataLoader(train_dataset, batch_size=24, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=24, shuffle=True)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = classifier(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
classifier.eval()
with torch.no_grad():
val_loss = 0
for j, batch in enumerate(test_loader):
inputs, labels = data
outputs = classifier(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
print(f'[{epoch + 1}, {i + 1:5d}] train_loss: {running_loss / 2000:.3f}, val_loss : {val_loss:.3f}')
running_loss = 0.0
val_loss = 0.0
classifier.train()
print('Finished Training')
def grid_search(agent, test_dataset):
delay_type = ['chance_delay', 'delay_on_thresh']
thresh = [0.1, 0.2, 0.3, 0.4, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.9]
param_list = []
gs_dict = {}
for dt in delay_type:
for t in thresh:
param_list.append((dt, t))
for tpl in param_list:
print(tpl)
eval_dict = agent.evaluate(
test_dataset,
action_strategy=tpl[0],
threshold=tpl[1]
)
delay_dict = delay_score(eval_dict=eval_dict, class_list=[0,1])
acc_dict = accuracy_score(eval_dict=eval_dict)
gs_dict[tpl] = {}
gs_dict[tpl]['results'] = eval_dict
gs_dict[tpl]['time_metrics'] = delay_dict
gs_dict[tpl]['acc_metrics'] = acc_dict
with open(os.path.join(MODELS_DIR, 'benchmark_classifier_grid_search_results.pkl'), 'wb') as handle:
pickle.dump(gs_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)
def main():
data_name = 'Heartbeat'
# Load training data
train_data, train_labels = load_data(data_name=data_name, data_type='TRAIN')
print(f"Number of train sequences {len(train_labels)}.")
cnts = np.unique(train_labels, return_counts=True)
print(cnts)
print(f"Number of abnormal class: {cnts[1][0]}")
print(f"Number of normal class: {cnts[1][1]}")
lst = [cnts[1][1]/len(train_labels), cnts[1][0]/len(train_labels)]
print(f"Class ratio: {lst}")
# Load testing data
test_data, test_labels = load_data(data_name=data_name, data_type='TEST')
print(f"Number of test sequences {len(test_labels)}.")
cnts = np.unique(test_labels, return_counts=True)
print(f"Number of abnormal class: {cnts[1][0]}")
print(f"Number of normal class: {cnts[1][1]}")
lst = [cnts[1][0]/len(test_labels), cnts[1][1]/len(test_labels)]
print(f"Class ratio: {lst}")
class_list = np.unique(train_labels)
action_dict = {i+1: v for i, v in enumerate(class_list) }
action_dict[0] = 'Delay'
num_feats = train_data.shape[-1]
class_dict = {i: v for i, v in enumerate(class_list)}
rev_class_dict = dict((v, k) for k, v in class_dict.items())
train_labels = [rev_class_dict[i] for i in train_labels]
test_labels = [rev_class_dict[i] for i in test_labels]
train_dataset = classDataset(data=train_data, labels=train_labels)
val_dataset = classDataset(data=test_data, labels=test_labels)
print(train_dataset)
agent = agentClassifier(
num_feats=num_feats,
class_list=class_list,
layer_1_size=128,
layer_2_size=128,
lr=0.001
)
agent.train(
epochs=20,
batch_size=24,
train_dataset=train_dataset,
val_dataset=val_dataset,
)
print("Training finished")
test_data, test_labels = load_data(data_name=data_name, data_type='TEST')
test_labels = [rev_class_dict[i] for i in test_labels]
test_dataset = classDataset(data=test_data, labels=test_labels, eval=True)
eval_dict = agent.evaluate(
test_dataset,
action_strategy='delay_on_thresh',
threshold=0.7
)
delay_dict = delay_score(eval_dict=eval_dict, class_list=[0,1])
acc_dict = accuracy_score(eval_dict=eval_dict)
print(delay_dict)
print(acc_dict)
grid_search(agent, test_dataset)
if __name__ == "__main__":
main()